.jpg)
3. AI 通才與專才模型「一, AI 算法特性 」
- 2024年10月13日
- 讀畢需時 1 分鐘
已更新:2024年11月5日

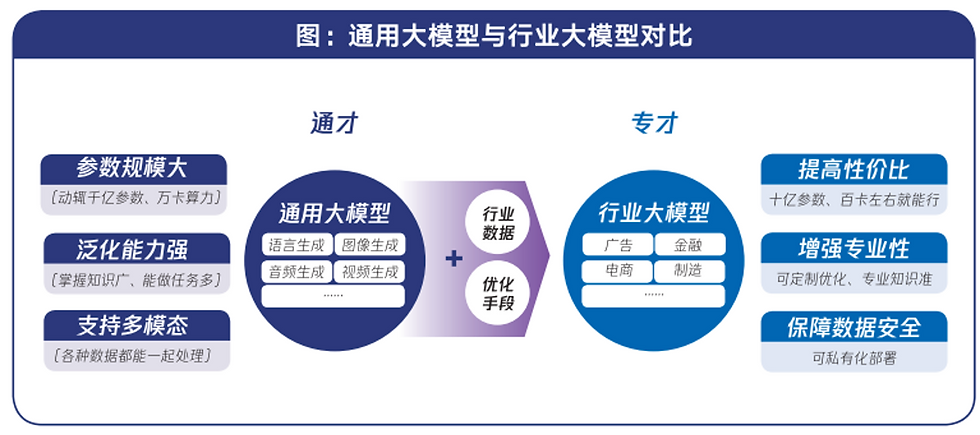
“通用大模型缺乏細分領域的專業知識,所以需要訓練行業大模型,然後緊密結合業務系統實現可落地的智能應用。而且很多企業的私有數據是不允許對外泄露的,比如金融、醫療的客戶信息和交互行爲,所以還需要提供大模型的私有化訓練和本地化部署。

“模型需要進一步的分級,如L0-L1-L2等從基礎模型、垂直模型到某個領域專家,來逐步實現專業性的提升。所謂的垂直領域模型,更多是一個特定訓練數據的加入,比如占到10-15%的預訓練占比,從而輸出行業大模型。
一, 是高性價比
行業大模型能在較小參數量模型的基礎上,通過相對低成本的再訓練或精調,達到較好的性能效果。
十億~百億級參數量的行業大模型是目前主流選擇,相比通用大模型動輒千億級以上的參數量能明顯節省開發成本;
二, 可專業定制
行業大模型可基于開源模型開發,能對模型結構、參數等按需調整,更好地適配個性化的應用需要。
通過模型即服務(MaaS,Model-as-a-Service)方式,機構可以從平臺對接的多種模型中快速選擇合適的使用,包括廠商已開發的行業大模型初始版本
三, 數據安全可控
行業大模型可采用私有化部署方式,機構能更放心地利用私有數據提升應用效果,减少數據安全的疑慮。



留言